
继英伟达(NVIDIA)推出 "与 RTX 聊天"(Chat with RTX)之后,AMD 现在又为用户提供了自己的本地化和基于 GPT 的 LLM 驱动的人工智能聊天机器人,该机器人可在 Ryzen AI CPU 和 Radeon 7000 GPU 上运行。
英伟达 RTX 聊天机器人有了竞争对手,因为 AMD 推出了自己的本地化 LLM 聊天机器人,可以在 Ryzen AI CPU 和 Radeon 7000 GPU 上运行。

上个月,英伟达(NVIDIA)推出了 "Chat with RTX" 人工智能聊天机器人,该机器人可在 RTX 40 和 RTX 30 GPU 上运行,并使用 TensorRT-LLM 功能集进行加速。现在,AMD 推出了自己的基于 LLM 的 GPT 聊天机器人,它可以在各种硬件上运行,如 Ryzen AI PC,包括配备 XDNA NPU 的 Ryzen 7000 和 Ryzen 8000 APU,以及配备 AI 加速内核的最新 Radeon 7000 GPU。
AMD 发布了一篇博文,提供了如何利用其硬件运行由基于 GPT 的 LLM(大型语言模型)驱动的本地化聊天机器人的设置指南。对于 AMD Ryzen AI CPU,您可以获得标准的 LM Studio Windows 版本,而 Radeon RX 7000 GPU 则可以获得 ROCm 技术预览版。完整指南共享如下:
1. 下载正确版本的 LM Studio:
用于 AMD Ryzen 处理器 用于 AMD Radeon RX 7000 系列显卡 LM Studio - Windows LM Studio – ROCm technical preview 2. 运行文件。
3. 在 "搜索" 选项卡中,根据要运行的内容复制并粘贴以下搜索词:
a. 如果要运行 Mistral 7b,请搜索 "TheBloke/OpenHermes-2.5-Mistral-7B-GGUF" 并从左边的结果中选择它。它通常会是第一个结果。本例中我们选择 Mistral。
b. 如果您想运行 LLAMA v2 7b,请搜索 "TheBloke/Llama-2-7B-Chat-GGUF" 并从左边的结果中选择它。它通常会是第一个结果。
c. 您也可以在此尝试其他模型。
4. 在右侧面板向下滚动,直到看到 Q4 K M 模型文件。点击下载。
a. 对于 Ryzen AI 上的大多数型号,我们推荐使用 Q4 K M。等待下载完成。
5. 转到聊天选项卡。从顶部中央的下拉菜单中选择模型,等待加载完成。
6. 如果您有 AMD Ryzen AI 电脑,就可以开始聊天了!
a. 如果您有 AMD Radeon 显卡,请:
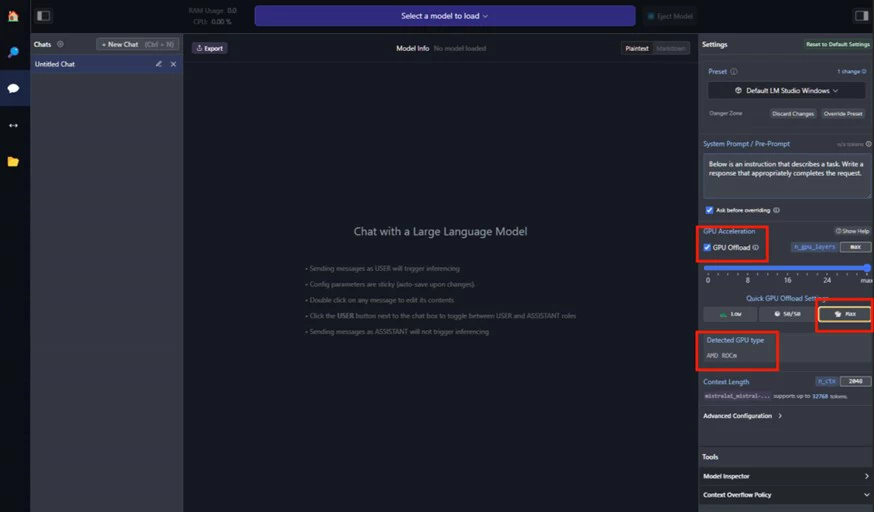
i. 勾选右侧面板上的 "GPU 卸载"。
ii. 将滑块一直移至 "最大"。
iii. 确保 AMD ROCm 显示为检测到的 GPU 类型。
iv. 开始聊天!



如果设置得当,拥有一个由人工智能驱动的本地化聊天机器人可以让生活和工作变得相对轻松。您可以高效地完成工作,并根据您的查询和 LLM 所针对的数据路径获得适当的结果。英伟达和 AMD 正在加快为消费级硬件提供人工智能功能的步伐,而这仅仅是一个开始,随着人工智能 PC 领域达到新的高度,我们期待着更多的创新。







![[WIN] AIMP 5.40 Build 2673](https://www.pcsofter.com/wp-content/uploads/2024/09/2024091211424647.webp)

![[WIN] FileZilla v3.69.0 正式版](https://www.pcsofter.com/wp-content/uploads/2023/04/2023042711185779.png)
![[WIN] ImageUSB v1.5.1007.0](https://www.pcsofter.com/wp-content/uploads/2025/04/2025041615462348.webp)

![[WIN] 格式工厂 FormatFactory v5.20.0](https://www.pcsofter.com/wp-content/uploads/2022/10/2023022410021170.jpg)
